
|

|
Большая Советская Энциклопедия (цитаты)
|

|
|
|
|
Математическая статистика | Математическая статистика (далее М), раздел математики, посвященный математическим методам систематизации, обработки и использования статистических данных для научных и практических выводов. При этом статистическими данными называются сведения о числе объектов в какой-либо более или менее обширной совокупности, обладающих теми или иными признаками (таковы, например, данные таблиц 1а и 2а).
Таблица 1а. - Распределение диаметра детали в мм, обнаруженное при статистическом исследовании массовой продукции (объяснение обозначений 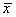 , , s см. в статье). , , s см. в статье).
Диаметр
|
Основная выборка
|
1-я выборка
|
2-я выборка
|
3-я выборка
|
13,05-13,09
|
-
|
-
|
1
|
1
|
13,10-13,14
|
2
|
-
|
-
|
-
|
13,15-13,19
|
1
|
-
|
1
|
1
|
13,20-13,24
|
8
|
-
|
-
|
-
|
13,25-13,29
|
17
|
1
|
2
|
1
|
13,30-13,34
|
27
|
1
|
1
|
2
|
13,35-13,39
|
30
|
2
|
3
|
1
|
13,40-13,44
|
37
|
2
|
1
|
1
|
13,45-13,49
|
27
|
1
|
-
|
-
|
13,50-13,54
|
25
|
2
|
1
|
-
|
13,55-13,59
|
17
|
-
|
-
|
-
|
13,60-13,64
|
7
|
1
|
-
|
2
|
13,65-13,69
|
2
|
-
|
-
|
1
|
Всего
|
200
|
10
|
10
|
10
|
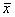
|
13,416
|
13,430
|
13,315
|
13,385
|
2
|
2,3910
|
0,0990
|
0,1472
|
0,3602
|
s
|
0,110
|
0,105
|
0,128
|
0,200
|
Таблица 1б. - Распределение диаметра детали основной выборки (из таблицы 1а) при более крупных интервалах группировки
Диаметр
|
Число деталей
|
13,00-13,24
|
11
|
13,25-13,49
|
138
|
13,50-13,74
|
51
|
Всего
|
200
|
Предмет и метод математической статистики. Статистическое описание совокупности объектов занимает промежуточное положение между индивидуальным описанием каждого из объектов совокупности, с одной стороны, и описанием совокупности по ее общим свойствам, совсем не требующим ее расчленения на отдельные объекты, - с другой. По сравнению с первым способом статистические данные всегда в большей или меньшей степени обезличены и имеют лишь ограниченную ценность в случаях, когда существенны именно индивидуальные данные (например, учитель, знакомясь с классом, получит лишь весьма предварительную ориентировку о положении дела из одной статистики числа выставленных его предшественником отличных, хороших, удовлетворительных и неудовлетворительных оценок). С другой стороны, по сравнению с данными о наблюдаемых извне суммарных свойствах совокупности статистические данные позволяют глубже проникнуть в существо дела. Например, данные гранулометрического анализа породы (то есть данные о распределении образующих породу частиц по размерам) дают ценную дополнительную информацию по сравнению с испытанием нерасчлененных образцов породы, позволяя в некоторой мере объяснить свойства породы, условия ее образования и прочее.
Метод исследования, опирающийся на рассмотрение статистических данных о тех или иных совокупностях объектов, называется статистическим. Статистический метод применяется в самых различных областях знания. Однако черты статистического метода в применении к объектам различной природы столь своеобразны, что было бы бессмысленно объединять, например, социально-экономическую статистику, физическую статистику (см. Статистическая физика), звездную статистику и тому подобное в одну науку.
Общие черты статистического метода в различных областях знания сводятся к подсчету числа объектов, входящих в те или иные группы, рассмотрению распределения количеств, признаков, применению выборочного метода (в случаях, когда детальное исследование всех объектов обширной совокупности затруднительно), использованию теории вероятностей при оценке достаточности числа наблюдений для тех или иных выводов и т. п. Эта формальная математическая сторона статистических методов исследования, безразличная к специфической природе изучаемых объектов, и составляет предмет М
Связь математической статистики с теорией вероятностей. Связь М с теорией вероятностей имеет в разных случаях различный характер. Вероятностей теория изучает не любые явления, а явления случайные и именно "вероятностно случайные", то есть такие, для которых имеет смысл говорить о соответствующих им распределениях вероятностей. Тем не менее, теория вероятностей играет определенную роль и при статистическом изучении массовых явлений любой природы, которые могут не относиться к категории вероятностно случайных. Это осуществляется через основанные на теории вероятностей теорию выборочного метода и теорию ошибок измерений (см. Ошибок теория). В этих случаях вероятностным закономерностям подчинены не сами изучаемые явления, а приемы их исследования.
Более важную роль играет теория вероятностей при статистическом исследовании вероятностных явлений. Здесь в полной мере находят применение такие основанные на теории вероятностей разделы М, как теория статистической проверки вероятностных гипотез, теория статистической оценки распределений вероятностей и входящих в них параметров и так далее. Область же применения этих более глубоких статистических методов значительно уже, так как здесь требуется, чтобы сами изучаемые явления были подчинены достаточно определенным вероятностным закономерностям. Например, статистическое изучение режима турбулентных водных потоков или флюктуаций в радиоприемных устройствах производится на основе теории стационарных случайных процессов. Однако применение той же теории к анализу экономических временных рядов может привести к грубым ошибкам ввиду того, что входящее в определение стационарного процесса допущение наличия сохраняющихся в течение длительного времени неизменных распределений вероятностей в этом случае, как правило, совершенно неприемлемо.
Вероятностные закономерности получают статистическое выражение (вероятности осуществляются приближенно в виде частот, а математические ожидания - в виде средних) в силу больших чисел закона.
Простейшие приемы статистического описания. Изучаемая совокупность из n объектов может по какому-либо качественному признаку А разбиваться на классы A1, A2, ..., Ar. Соответствующее этому разбиению статистическое распределение задается при помощи указания численностей (частот) n1, n2, ..., nr, (где 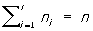 ) отдельных классов. Вместо численностей ni часто указывают соответствующие относительные частоты (частости) hi = ni / n (удовлетворяющие, очевидно, соотношению ) отдельных классов. Вместо численностей ni часто указывают соответствующие относительные частоты (частости) hi = ni / n (удовлетворяющие, очевидно, соотношению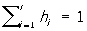 ). Если изучению подлежит некоторый количественный признак, то его распределение в совокупности из n объектов можно задать, перечислив непосредственно наблюденные значения признака: х1, x2, ..., xn, например, в порядке их возрастания. Однако при больших n такой способ громоздок и в то же время не выявляет отчетливо существенных свойств распределения (подробнее о способах изображения и простейших характеристиках распределения одного количественного признака см. Распределения). При сколько-либо больших n на практике обычно совсем не составляют полных таблиц наблюденных значений xi, а исходят во всей дальнейшей работе из таблиц, содержащих лишь численности классов, получающихся при группировке наблюденных значений по надлежаще выбранным интервалам. ). Если изучению подлежит некоторый количественный признак, то его распределение в совокупности из n объектов можно задать, перечислив непосредственно наблюденные значения признака: х1, x2, ..., xn, например, в порядке их возрастания. Однако при больших n такой способ громоздок и в то же время не выявляет отчетливо существенных свойств распределения (подробнее о способах изображения и простейших характеристиках распределения одного количественного признака см. Распределения). При сколько-либо больших n на практике обычно совсем не составляют полных таблиц наблюденных значений xi, а исходят во всей дальнейшей работе из таблиц, содержащих лишь численности классов, получающихся при группировке наблюденных значений по надлежаще выбранным интервалам.
Например, в первом столбце таблицы 1а даны результаты измерения 200 диаметров деталей, группированные по интервалам длиной 0,05 мм. Основная выборка соответствует нормальному ходу технологического процесса, 1-я, 2-я и 3-я выборки сделаны через некоторые промежутки времени для проверки устойчивости этого нормального хода производства. В таблице 1б результаты измерения деталей основной выборки даны при группировке по интервалам длиной 0,25 мм.
Обычно группировка по 10-20 интервалам, в каждый из которых попадает не более 15-20 % значений xi, оказывается достаточной для довольно полного выявления всех существенных свойств распределения и надежного вычисления по групповым численностям основных характеристик распределения (см. о них ниже). Составленная по таким группированным данным гистограмма наглядно изображает распределение. Гистограмма, составленная на основе группировки с маленькими интервалами, обычно многовершинная и не отражает наглядно существенных свойств распределения.
В качестве примера на рис. 1 дана гистограмма распределения 200 диаметров, соответствующая данным первого столбца таблицы 1а, а на рис. 3 - гистограмма того же распределения (соответствующая таблица не приводится ввиду ее громоздкости) при интервале 0,01 мм. С другой стороны, группировка по слишком крупным интервалам может привести к потере ясного представления о характере распределения и к грубым ошибкам при вычислении среднего и других характеристик распределения (см. таблицу 1б и соответствующую гистограмму на рис. 2).
В пределах М вопрос об интервалах группировки может быть рассмотрен только с формальной стороны: полноты математического описания распределения, точности вычисления средних по сгруппированным данным и так далее. О группировке, имеющей целью выделить качественно различные группы в изучаемой совокупности, см. Статистические группировки.
При изучении совместного распределения двух признаков пользуются таблицами с двумя входами. Примером совместного распределения двух качеств, признаков может служить таблица 2а. В общем случае, когда по признаку А материал разбит на классы A1, A2, ..., Ar, а по признаку В - на классы 1, 2, ..., s, таблица состоит из численностей nij объектов, принадлежащих одновременно классам Ai и j). Суммируя их по формулам
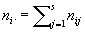 , , 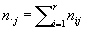 , ,
получают численности самих классов Ai и j; очевидно, что
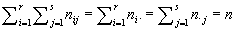 , ,
где n - численность всей изучаемой совокупности. В зависимости от целей дальнейшего исследования вычисляют те или иные из относительных частот
hij = nij / n, hi. = ni. / n, h.j = n..j / n, hi(j) = nij / n.j, h(i)j = nij / ni..
Например, при изучении влияния вдыхания сыворотки на заболевание гриппом по таблице 2а естественно вычислить относительные частоты, данные в таблице 2б.
Таблица 2а. - Распределение заболевших и не заболевших гриппом среди работников Центрального универмага в Москве, вдыхавших и не вдыхавших противогриппозную сыворотку (1939)
|
Не заболевшие
|
Заболевшие
|
Всего
|
Не вдыхавшие
|
1675
|
150
|
1825
|
Вдыхавшие
|
497
|
4
|
501
|
Всего
|
2172
|
154
|
2326
|
Таблица 2б. - Относительные частоты (соответствующие данным таблицы 2а)
|
Не заболевшие
|
Заболевшие
|
Всего
|
Не вдыхавшие
|
0,918
|
0,082
|
1,000
|
Вдыхавшие
|
0,992
|
0,008
|
1,000
|
Пример таблицы для совместного распределения двух количеств, признаков см. в статье Корреляция. Таблица 1а служит примером смешанного случая: материал группируется по одному качеств, признаку (принадлежность к основной выборке, произведенной для определения среднего уровня производственного процесса, и к трем выборкам, произведенным в различные моменты времени для проверки сохранения этого нормального среднего уровня) и по одному количеств, признаку (диаметр деталей).
Простейшими сводными характеристиками распределения одного количественного признака являются среднее
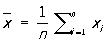 , ,
и среднее квадратичное отклонение
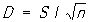 , ,
где
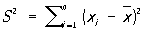
При вычислении 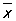 , 2 и D по группированным данным пользуются формулами , 2 и D по группированным данным пользуются формулами
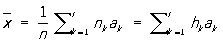 , ,
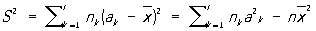
или
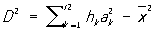 , ,
где r - число интервалов группировки, ak - их середины (в случае таблицы 1а - 13,07; 13,12; 13,17; 13,22 и т. д.). Если материал сгруппирован по слишком крупным интервалам, то такой подсчет дает слишком грубые результаты. Иногда в таких случаях полезно прибегать к специальным поправкам на группировку. Однако эти поправки имеет смысл вводить лишь при условии выполнения определенных вероятностных предположений.
О совместных распределениях двух и большего числа признаков см. Корреляция, Корреляционный анализ, Регрессия, Регрессионный анализ.
Связь статистических распределений с вероятностными. Оценка параметров.
Проверка вероятностных гипотез. Выше были изложены лишь некоторые избранные простейшие приемы статистического описания, представляющего собой довольно обширную дисциплину с хорошо разработанной системой понятий и техникой вычислений. Приемы статистического описания интересны, однако не сами по себе, а в качестве средства для получения из статистического материала выводов о закономерностях, которым подчиняются изучаемые явления, и о причинах, приводящих в каждом отд. случае к тем или иным наблюденным статистическим распределениям.
Например, данные, приведенные в таблице 2а, естественно связать с такой теоретической схемой. Заболевание гриппом каждого отдельного работника универмага следует считать случайным событием, так как общие условия работы и жизни обследованных работников универмага могут определять не сам факт заболевания такого-то и такого-то работника, а лишь некоторую вероятность заболевания. Вероятности заболевания для вдыхавших сыворотку (p1) и для не вдыхавших (p0), судя по статистическим данным, различны: эти данные дают основания предполагать, что p1 существенно меньше p0. Перед М возникает задача: по наблюденным частотам h1 = 4/501 " 0,008 и h0 = 150/1825 " 0,082 оценить вероятности p1 и p0 и проверить, достаточен ли статистический материал для того, чтобы считать установленным, что p1 < p0 (то есть что вдыхание сыворотки действительно уменьшает вероятность заболевания). Утвердительный ответ на поставленный вопрос в случае данных таблицы 2а достаточно убедителен и без тонких средств М Но в более сомнительных случаях необходимо прибегать к разработанным М специальным критериям.
Данные первого столбца таблицы 1а собраны с целью установления точности изготовления деталей, расчетный диаметр которых равен 13,40 мм, при нормальном ходе производства. Простейшим допущением, которое может быть в этом случае обосновано некоторыми теоретическими соображениями, является предположение, что диаметры отдельных деталей можно рассматривать как случайные величины X, подчиненные нормальному распределению вероятностей
{X<x} = 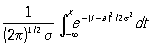 . (1) . (1)
Если это допущение верно, то параметры a и s2 - среднее и дисперсию вероятностного распределения - можно с достаточной точностью оценить по соответствующим характеристикам статистического распределения (так как число наблюдений n = 200 достаточно велико). В качестве оценки для теоретической дисперсии s2 предпочитают не статистическую дисперсию D2 = 2/ n, а несмещенную оценку
s2 = 2/ (n - 1).
Для теоретического среднего квадратичного отклонения не существует общего (пригодного при любом распределении вероятностей) выражения несмещенной оценки. В качестве оценки (вообще говоря, смещенной) для s чаще всего употребляют s. Точность оценок 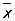 и s для a и s указывается соответствующими дисперсиями, которые в случае нормального распределения (1) имеют вид и s для a и s указывается соответствующими дисперсиями, которые в случае нормального распределения (1) имеют вид
s2a = s2/ n ~ s2/ n,
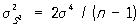 ~ 2s4/ n, ~ 2s4/ n,
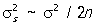 ~ s2/ 2n, ~ s2/ 2n,
где знак ~ обозначает приближенное равенство при больших n. Таким образом, уславливаясь прибавлять к оценкам со знаком ± их среднее квадратичное отклонение, имеем при больших n в предположении нормального распределения (1):
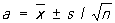 , , 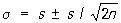 . (2) . (2)
Для данных первого столбца таблицы 1а формулы (2) дают
a = 13,416 ± 0,008,
s = 0,110 ± 0,006.
Объем выборки n = 200 достаточен для законности пользования этими формулами теории больших выборок.
Дальнейшие сведения об оценке параметров теоретических распределений вероятностей см. в статьях Статистические оценки, Доверительные границы. О способах, при помощи которых по данным первого столбца таблицы 1а можно было бы проверить исходные гипотезы нормальности распределения и независимости наблюдений, см. в статьях Распределения, Непараметрические методы, Статистическая проверка гипотез.
При рассмотрении данных следующих столбцов таблицы 1а, каждый из которых составлен на основе 10 измерений, употребление формул теории больших выборок, установленных лишь в качестве предельных формул при n ® ¥, может служить только для первой ориентировки. В качестве приближенных оценок параметров a и s по-прежнему употребляются величины 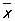 и s, но для оценки точности и надежности таких оценок необходимо применять теорию малых выборок. При сравнении по правилам М выписанных в последних строках таблицы 1а значений и s, но для оценки точности и надежности таких оценок необходимо применять теорию малых выборок. При сравнении по правилам М выписанных в последних строках таблицы 1а значений 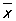 и s для трех выборок с нормальными значениями a и s, оцененными по первому столбцу таблицы, можно сделать следующие выводы: первая выборка не дает оснований предполагать существенного изменения хода производственного процесса, вторая выборка дает основание к заключению об уменьшении среднего диаметра а, третья выборка - к заключению об увеличении дисперсии. и s для трех выборок с нормальными значениями a и s, оцененными по первому столбцу таблицы, можно сделать следующие выводы: первая выборка не дает оснований предполагать существенного изменения хода производственного процесса, вторая выборка дает основание к заключению об уменьшении среднего диаметра а, третья выборка - к заключению об увеличении дисперсии.
Все основанные на теории вероятностей правила статистической оценки параметров и проверки гипотез действуют лишь с определенным значимости уровнем w < 1, то есть могут приводить к ошибочным результатам с вероятностью a = 1 - w. Например, если в предположении нормального распределения и известной теоретической дисперсии s2 производить оценку a по 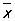 по правилу по правилу
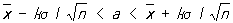 , ,
то вероятность ошибки будет равна a, связанному с k соотношением (см. таблицу 3);
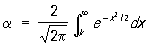 . .
Вопрос о рациональном выборе уровня значимости в данных конкретных условиях (например, при разработке правил статистического контроля массовой продукции) является весьма существенным. При этом желанию применять правила лишь с высоким (близким к единице) уровнем значимости противостоит то обстоятельство, что при ограниченном числе наблюдений такие правила позволяют сделать лишь очень бедные выводы (не дают возможности установить неравенство вероятностей даже при заметном неравенстве частот и т. д.).
Таблица 3. - Зависимость a и w = 1 - a от k.
k
|
1,96
|
2,58
|
3,00
|
3,29
|
a
|
0,050
|
0,010
|
0,003
|
0,001
|
w
|
0,950
|
0,990
|
0,997
|
0,999
|
Выборочный метод. В предыдущем разделе результаты наблюдений, используемых для оценки распределения вероятностей или его параметров, подразумевались (хотя это и не оговаривалось) независимыми (см. Вероятностей теория и особенно Независимость). Хорошо изученным примером использования зависимых наблюдений может служить оценка статистического распределения или его параметров в "генеральной совокупности" из объектов по произведенной из нее "выборке", содержащей n < объектов.
Терминологическое замечание. Часто совокупность n наблюдений, сделанных для оценки распределения вероятностей, также называют выборкой. Этим объясняется, например, происхождение употребленного выше термина "теория малых выборок". Эта терминология связана с тем, что часто распределение вероятностей представляют себе в виде статистического распределения в воображаемой бесконечной "генеральной совокупности" и условно считают, что наблюдаемые n объектов "выбираются" из этой совокупности. Эти представления не имеют отчетливого содержания. В собственном смысле слова выборочный метод всегда предполагает исходную конечную генеральную совокупность.
Примером применения выборочного метода может служить следующий. Пусть в партии из изделий имеется L дефектных. Из партии отбирается случайным образом n < изделий (например, n = 100 при = 10 000). Вероятность того, что число l дефектных изделий в выборке будет равно m, равна
{l = m} = 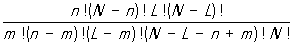
Таким образом, l и соответствующая относительная частота h = l / n оказываются случайными величинами, распределение которых зависит от параметра L или, что то же самое, от параметра Н = L / . Задача оценки относительной частоты Н по выборочной относительной частоте h очень похожа на задачу оценки вероятности р по относительной частоте h при n независимых испытаниях. При больших n с вероятностью, близкой к единице, в задаче об оценке вероятности имеет место приближенное равенство р ~ h, а в задаче об оценке относительной частоты - приближенное равенство ~ h. Однако в задаче об оценке Н формулы сложнее, а отклонения h от Н в среднем несколько меньше, чем отклонения h от р в задаче об оценке вероятности (при том же n). Таким образом, оценка доли Н дефектных изделий в партии по доле h дефектных изделий в выборке при данном объеме выборки n производится всегда (при любом ) несколько точнее, чем оценка вероятности р по относительной частоте h при независимых испытаниях. Когда /n ® ¥, формулы задачи о выборке переходят асимптотически в формулы задачи об оценке вероятности р. См. также Выборочный метод.
Дальнейшие задачи математической статистики. Упоминавшиеся выше способы оценки параметров и проверки гипотез основаны на предположении, что число наблюдений, необходимых для достижения заданной точности выводов, определяют заранее (до проведения испытаний). Однако часто априорное определение числа наблюдений нецелесообразно, так как, не фиксируя число опытов заранее, а определяя его в ходе эксперимента, можно уменьшить его математическое ожидание. Сначала это обстоятельство было подмечено на примере выбора одной из двух гипотез по последовательности независимых испытаний. Соответствующая процедура (впервые предложенная в связи с задачами приемочного статистического контроля) состоит в следующем: на каждом шаге по результатам уже проведенных наблюдений решают а) провести ли следующее испытание, или б) прекратить испытания и принять первую гипотезу, или в) прекратить испытания и принять вторую гипотезу. При надлежащем подборе количеств, характеристик подобной процедуры можно добиться (при той же точности выводов) сокращения числа наблюдений в среднем почти вдвое по сравнению с процедурой выборки фиксированного объема (см. Последовательный анализ). Развитие методов последовательного анализа привело, с одной стороны, к изучению управляемых случайных процессов, с другой - к появлению общей теории статистических решений. Эта теория исходит из того, что результаты последовательно проводимых наблюдений служат основой принятия некоторых решений (промежуточных - продолжать испытания или нет, и окончательных - в случае прекращения испытаний). В задачах оценки параметров окончательные решения суть числа (значение оценок), в задачах проверки гипотез - принимаемые гипотезы. Цель теории - указать правила принятия решений, минимизирующих средний риск или убыток (риск зависит и от вероятностных распределений результатов наблюдений, и от принимаемого окончательного решения, и от расходов на проведение испытаний и т. п.).
Вопросы целесообразного распределения усилий при проведении статистического анализа явлений рассматриваются в теории планирования эксперимента, ставшей важной частью современной М
Наряду с развитием и уточнением общих понятий М развиваются и ее отдельные разделы, такие, как дисперсионный анализ, статистический анализ случайных процессов, статистический анализ многомерный. Появились новые оценки в регрессионном анализе (см. также Стохастическая аппроксимация). Большую роль в задачах М играет так называемый байесовский подход (см. Статистические решения).
Историческая справка. Первые начала М можно найти уже в сочинениях создателей теории вероятностей - Я. Бернулли (конец 17 - начало 18 веков), П. Лапласа (2-я половина 18 - начало 19 веков) и С. Пуассона (1-я половина 19 века). В России методы М в применении к демографии и страховому делу развивал на основе теории вероятностей В. Я. Буняковский (1846). Решающее значение для всего дальнейшего развития М имели работы русской классической школы теории вероятностей 2-й половины 19 - начала 20 веков (П. Л. Чебышев, А. А. Марков, А. М. Ляпунов, С. Н. Бернштейн). Многие вопросы теории статистических оценок были по существу разработаны на основе теории ошибок и метода наименьших квадратов (К. Гаусс (1-я половина 19 века) и А. А. Марков (конец 19 - начало 20 веков)). Работы А. Кетле (19 век, Бельгия), Ф. Гальтона (19 век, Великобритания) и К. Пирсона (конец 19 - начало 20 веков, Великобритания) имели большое значение, но по уровню использования достижений теории вероятностей отставали от работ русской школы. К. Пирсоном была широко развернута работа по составлению таблиц функций, необходимых для применения методов М В создании теории малых выборок, общей теории статистических оценок и проверки гипотез (освобожденной от предположений о наличии априорных распределений), последовательного анализа весьма значительна роль представителей англо-американской школы (Стьюдент (псевдоним У. Госсета), Р. Фишер, Э. Пирсон - Великобритания, Ю. Нейман, А. Вальд - США), деятельность которых началась в 20-х годах 20 века. В СССР значительные результаты в области М получены В. И. Романовским, Е. Е. Слуцким, которому принадлежат важные работы по статистике связанных стационарных рядов, Н. В. Смирновым, заложившим основы теории непараметрических методов М, Ю. В. Линником, обогатившим аналитический аппарат М новыми методами. На основе М особенно интенсивно разрабатываются статистические методы исследования и контроля массового производства, статистические методы в области физики, гидрологии, климатологии, звездной астрономии, биологии, медицины и другие.
Существует несколько журналов, публикующих работы по М, в том числе "Annals of Statistics" (до 1973 "Annals of Mathematical Statistics"), "International Statistical Institute Review", "Biometrika", "Journal of the Royal Statistical Society". Имеются научные ассоциации, поддерживающие исследования по М и ее применениям. Важную роль играет Международный статистический институт () с центром в Амстердаме и созданная при нем Международная ассоциация по статистическим методам в естественых науках (IASPS).
Лит.: Крамер Г., Математические методы статистики, перевод с английского, М., 1948; Ван-дер-Варден Б. Л., М, перевод с немецкого, М., 1960; Смирнов Н. В., Дунин-Барковский И. В., Курс теории вероятностей и математической статистики для технических приложений, 3 изд., М., 1969; Большев Л. Н., Смирнов Н. В., Таблицы математической статистики, М., 1968; Линник Ю. В., Метод наименьших квадратов ..., 2 изд., М., 1962; Хальд А., М с техническими приложениями, перевод с английского, М., 1956; Андерсон Т., Введение в многомерный статистический анализ, перевод с английского, М., 1963; Кендалл М. Дж., Стьюарт А., Теория распределений, перевод с английского, М., 1966.
А. Н. Колмогоров, Ю. В. Прохоров.
|
Для поиска, наберите искомое слово (или его часть) в поле поиска
|
|
 |
 |
 |
|
|
|
Новости 30.10.2024 22:37:11
|
|
|
|
|
|
|
|
|
|
|


