
|

|
Большая Советская Энциклопедия (цитаты)
|

|
|
|
|
Кодирование | Кодирование (далее К) операция отождествления символов или групп символов одного кода с символами или группами символов другого кода. Необходимость К возникает прежде всего из потребности приспособить форму сообщения к данному каналу связи или какому-либо другому устройству, предназначенному для преобразования или хранению информации. Так, сообщения представленные в виде последовательности букв, например русского языка, и цифр, с помощью телеграфных кодов преобразуются в определенные комбинации посылок тока. При вводе в вычислительные устройства обычно пользуются преобразованием числовых данных из десятичной системы счисления в двоичную и т.д. (см. Кодирующее устройство).
К в информации теории применяют для достижения следующих целей: во-первых, для уменьшения так называемой избыточности сообщений и, во-вторых, для уменьшения влияния помех, искажающих сообщения при передаче по каналам связи (см. Шеннона теорема). Поэтому выбор нового кода стремятся наиболее удачным образом согласовать со статистической структурой рассматриваемого источника сообщений. В какой-то степени это согласование имеется уже в коде телеграфном, в котором чаще встречающиеся буквы обозначаются более короткими комбинациями точек и тире.
Приемы, применяемые в теории информации для достижения указанного согласования, можно пояснить на примере построения "экономных" двоичных кодов. Пусть канал может передавать только символы 0 и 1, затрачивая на каждый одно и то же время t. Для уменьшения времени передачи (или, что то же самое, увеличения ее скорости) целесообразно до передачи кодировать сообщения таким образом, чтобы средняя длина L кодового обозначения была наименьшей. Пусть х1, х2,..., xn обозначают возможные сообщения некоторого источника, a p1, р2,..., р2 — соответствующие им вероятности. Тогда, как устанавливается в теории информации, при любом способе К,
где L ³ Н, (1)
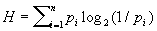 — —
энтропия источника. Граница для L в формуле (1) может не достигаться. Однако при любых pi существует метод К (метод Шеннона — Фэно), для которого
L £ Н + 1. (2)
Метод состоит в том, что сообщения располагаются в порядке убывания вероятностей и полученный ряд делится на 2 части с вероятностями, по возможности близкими друг к другу. В качестве 1-го двоичного знака принимают 0 в 1-й части и 1 — во 2-й. Подобным же образом делят пополам каждую из частей и выбирают 2-й двоичный знак и т.д., пока не придут к частям, содержащим только по одному сообщению.
Пример 1. Пусть n = 4 и p1=9/16, р2 = р3 = 3/16, p4= 1/16. Применение метода иллюстрируется табл.:
х,
|
Pi
|
Кодовое обозначение
|
х1
|
9/16
|
0
|
|
|
х2
|
3/16
|
1
|
0
|
|
х3
|
3/16
|
1
|
1
|
0
|
х3
|
1/16
|
1
|
1
|
1
|
данном случае L = 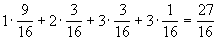 = 1,688 и можно показать, что никакой др. код не дает меньшего значения. В то же время Н = 1,623. Все сказанное применимо и к случаю, когда алфавит нового кода содержит не 2, как предполагалось выше, а m > 2 букв. При этом лишь величина Н в формулах (1) и (2) должна быть заменена величиной /log2m. = 1,688 и можно показать, что никакой др. код не дает меньшего значения. В то же время Н = 1,623. Все сказанное применимо и к случаю, когда алфавит нового кода содержит не 2, как предполагалось выше, а m > 2 букв. При этом лишь величина Н в формулах (1) и (2) должна быть заменена величиной /log2m.
Задача о "сжатии" записи сообщений в данном алфавите (то есть задача об уменьшении избыточности) может быть решена на основе метода Шеннона — Фэно. Действительно, с одной стороны, если сообщения представлены последовательностями букв длины из м-буквенного алфавита, то их средняя длина L после К всегда удовлетворяет неравенству L ³/log2т, где Н — энтропия источника на букву. С другой стороны, при сколь угодно малом e>0 можно добиться выполнения при всех достаточно больших неравенства
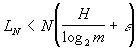 . (3) . (3)
С этой целью пользуются К "блоками": по данному e выбирают натуральное число s и делят каждое сообщение на равные части — "блоки", содержащие по s букв. Затем эти блоки кодируют методом Шеннона — Фэно в тот же алфавит. Тогда при достаточно больших будет выполнено неравенство (3). Справедливость этого утверждения легче всего понять, рассматривая случай, когда источником является последовательность независимых символов 0 и 1, появляющихся с вероятностями соответственно р и q, p¹q. Энтропия на блок равна s-кpaтной энтропии на одну букву, т. е. равна sH =s (plog2 1/p+qlog2 1/q). Кодовое обозначение блока требует в среднем не более sH + 1 двоичных знаков. Поэтому для сообщения длины букв L£(1+/s) (sH+1) = (+1/s) (1+s/), что при достаточно больших s и /s приводит к неравенству (3). При таком К энтропия на букву приближается к своему максимальному значению — единице, а избыточность — к нулю.
Пример 2. Пусть источником сообщений является последовательность независимых знаков 0 и 1, в которой вероятность появления нуля равна р = 3/4, а единицы q = 1/4. Здесь энтропия Н на букву равна 0,811, а избыточность — 0,189. Наименьшие блоки (s = 2), то есть 00, 01, 10, 11, имеют соответственно вероятности р2 = 9/16, pq = 3/16, qp = 3/16, q2 =1/16. Применение метода Шеннона — Фэно (см. пример 1) приводит к правилу К: 00®0, 01®10, 10®110, 11®111. При этом, например, сообщение 00111000... примет вид 01111100... На каждую букву сообщения в прежней форме приходится в среднем 27/32 = 0,844 буквы в новой форме (при нижней границе коэффициента сжатия, равной Н = 0,811). Энтропия на букву в новой последовательности равна 0,811/0,844 = 0,961, а избыточность равна 0,039.
К, уменьшающее помехи, превратилось в большой раздел теории информации, со своим собственным математическим аппаратом, в значительной мере чисто алгебраическим (см. Канал, Шеннона теорема и литературу при этих статьях).
Ю. В. Прохоров. |
Для поиска, наберите искомое слово (или его часть) в поле поиска
|
|
 |
 |
 |
|
|
|
Новости 21.11.2024 12:09:11
|
|
|
|
|
|
|
|
|
|
|


